|
Zili Lin, Wenyao Zhang^, Yuyang Zhang, Zekun Qi, Junyan Lin, Hanxin Zhu, Jiaolong Yang, Zhibo Chen, Yao Mu, Xiaokang Yang, Xin Jin, Wenjun Zeng ArXiv Preprint, 2026 [arXiv] [Project Page] [Code] [Huggingface] We introduce DeformGen, a dynamics-based augmentation framework for deformable manipulation that generates physically plausible topology variations and warps manipulation trajectories through deformation fields to improve policy generalization from limited demonstrations. |
|
|
Yuyang Zhang*, Wenyao Zhang*†, Zekun Qi, He Zhang, Haitao Lin, Jingbo Zhang, Yao Mu, Xiaokang Yang, Wenjun Zeng, Xin Jin ArXiv Preprint, 2026 [arXiv] [Project Page] [Code] [Huggingface] We introduce ImageWAM, a simple world-action model that repurposes pretrained image editing models for robot action prediction, using editing KV caches as compact world-action context to reduce inference cost while improving policy performance. |
|
|
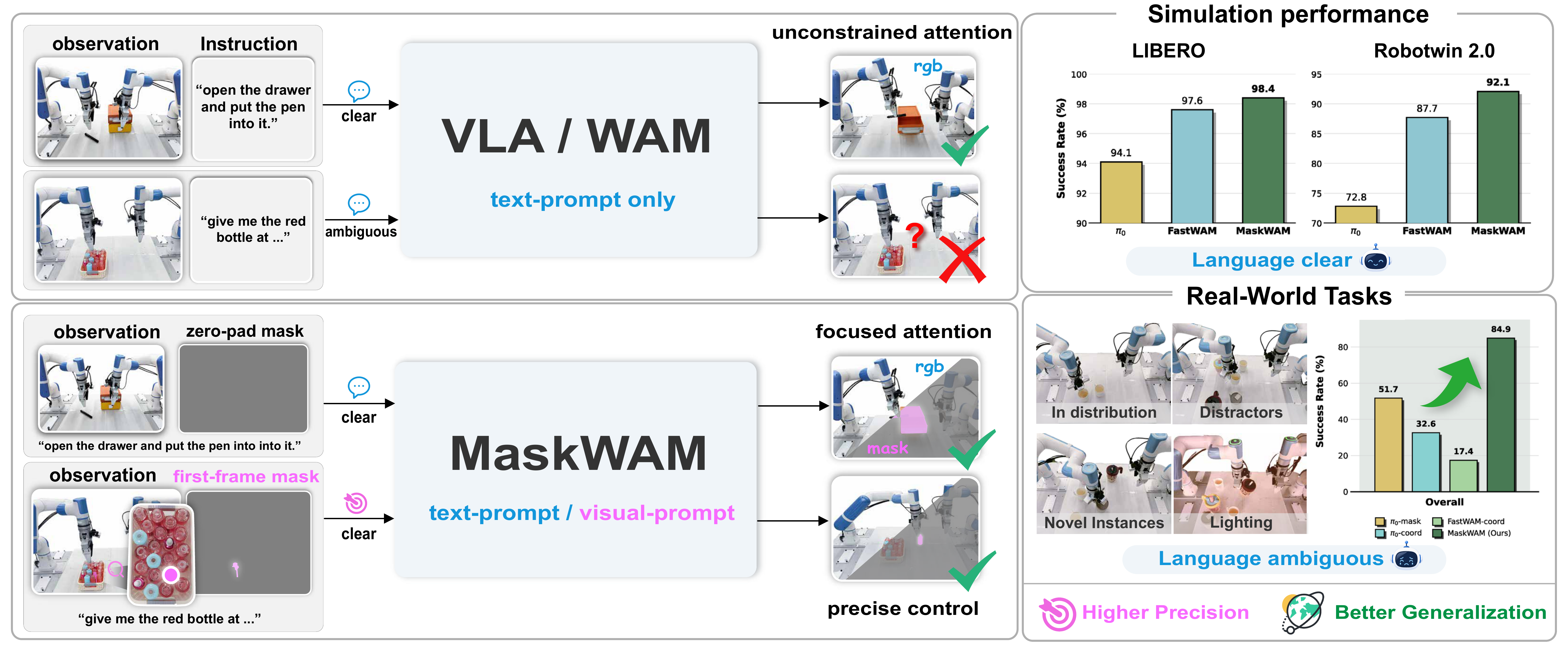
Hanyang Yu, Haitao Lin, Jingbo Zhang, Wenyao Zhang, Chenghao Gu, Heng Li, Ping Tan ArXiv Preprint, 2026 [arXiv] [Project Page] [Code] We introduce MaskWAM, an object-centric world-action model that unifies mask prompting and mask prediction to provide spatially grounded supervision and robust policy generalization in language-clear and language-ambiguous manipulation tasks. |
|
Zekun Qi*, Xuchuan Chen*, Dairu Liu*, Chenghuai Lin*, Yunrui Lian, Sikai Liang, Zhikai Zhang, Yu Guan, Jilong Wang, Wenyao Zhang, Xinqiang Yu, He Wang, Li Yi IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2026) [arXiv] [Project Page] [Code] We introduce Humanoid-GPT, a GPT-style Transformer with causal attention trained on a 2B-frame retargeted motion corpus for whole-body control, achieving unprecedented zero-shot generalization to unseen motions and control tasks. |
|
|
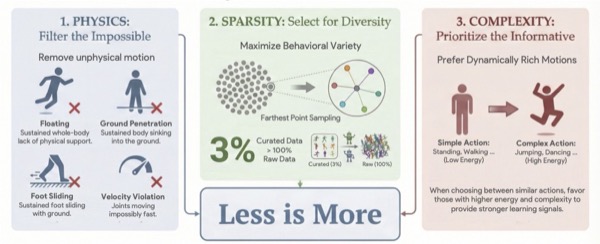
Yu Guan*, Zekun Qi*, Chenghuai Lin, Xuchuan Chen, Dairu Liu, Wenyao Zhang, Jilong Wang, Xinqiang Yu, He Wang, Li Yi International Conference on Machine Learning (ICML 2026) [arXiv] [Project Page] We introduce LIMMT, a data-centric framework for humanoid motion tracking that curates motion data through physics feasibility, action diversity, and action complexity, showing that training on just 3% of curated data outperforms using full corpora. |
|
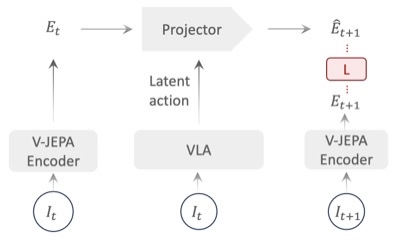
Jingwen Sun*, Wenyao Zhang*, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, Zhibo Chen European Conference on Computer Vision (ECCV 2026) [arXiv] [Project Page] [Code] We introduce VLA-JEPA, a JEPA-style pretraining framework that learns action-relevant transition semantics by predicting future latent states without pixel reconstruction or information leakage, achieving consistent gains in generalization and robustness over existing methods. |

|
Baorui Peng*, Wenyao Zhang*, Liang Xu, Zekun Qi, Jiazhao Zhang, Hongsi Liu, Wenjun Zeng, Xin Jin ArXiv Preprint, 2026 [arXiv] We introduce ReWorld, a framework that employs reinforcement learning to align video-based embodied world models with physical realism, task completion capability, embodiment plausibility, and visual quality through a hierarchical reward model trained on a large-scale video preference dataset. |
|
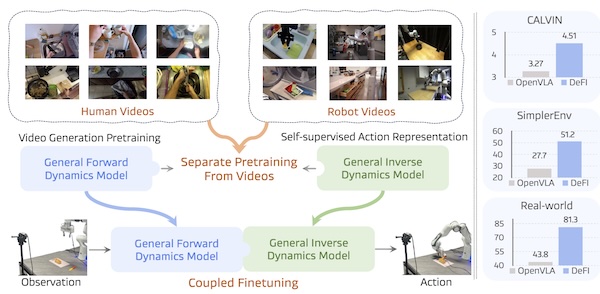
Wenyao Zhang*, Bozhou Zhang*, Zekun Qi, Wenjun Zeng, Xin Jin, Li Zhang, International Conference on Learning Representations (ICLR 2026) [paper] We propose DeFI, decoupling visual forward and inverse dynamics pretraining with a General Forward Dynamics Model (GFDM) for future prediction and a General Inverse Dynamics Model (GIDM) for latent actions from video, then unified finetuning for robot manipulation. |
|
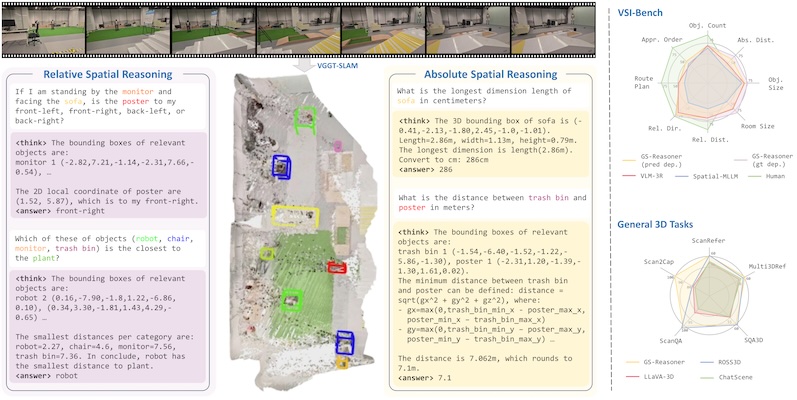
Mengdi Jia*, Zekun Qi*, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, Li Yi International Conference on Learning Representations (ICLR 2026) [arXiv] [Project Page] [Code] [Huggingface] Based on cognitive psychology, we introduce a comprehensive and complex spatial reasoning benchmark, including 50 detailed categories and 1.5K manual labeled QA pairs. |
|
|
Yiming Chen, Zekun Qi, Wenyao Zhang, Xin Jin, Li Zhang, Peidong Liu International Conference on Learning Representations (ICLR 2026) [arXiv] [Project Page] [Code] [HuggingFace] We propose DeFI, decoupling visual forward and inverse dynamics pretraining with a General Forward Dynamics Model (GFDM) for future prediction and a General Inverse Dynamics Model (GIDM) for latent actions from video, then unified finetuning for robot manipulation. |
|
Tianyu Xu*, Jiawei Chen*, Jiazhao Zhang*, Wenyao Zhang, Zekun Qi, Minghan Li, Zhizheng Zhang, He Wang European Conference on Computer Vision (ECCV 2026) [arXiv] [Project Page] We present MM-Nav a multi-view VLA system with 360° perception. The model is trained on large-scale expert navigation data collected from multiple reinforcement learning agents, demonstrating robust generalization in complex navigation scenarios. |
|

|
Wenyao Zhang*, Hongsi Liu*, Zekun Qi*, Yunnan Wang*, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, Xin Jin Annual Conference on Neural Information Processing Systems (NeurIPS 2025) [arXiv] [Project Page] [Code] [Huggingface] We recast the vision–language–action model as a perception–prediction–action model and make the model explicitly predict a compact set of dynamic, spatial and high- level semantic information, supplying concise yet comprehensive look-ahead cues for planning. |
|
Zekun Qi*, Wenyao Zhang*, Yufei Ding*, Runpei Dong, Xinqiang Yu, Jingwen Li, Lingyun xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang, He Wang, Li Yi Annual Conference on Neural Information Processing Systems (NeurIPS 2025) Spotlight [arXiv] [Project Page] [Code] [Huggingface] We introduce the concept of semantic orientation, representing the object orientation condition on open vocabulary language. |
|
|
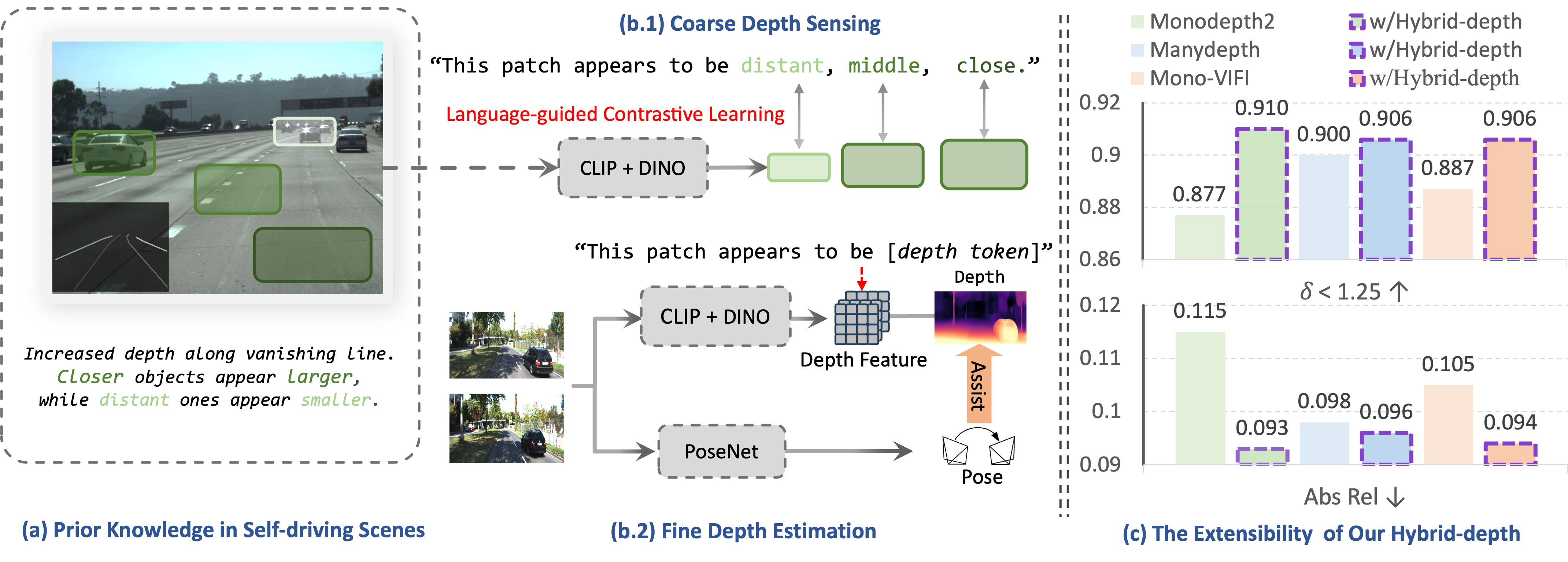
Wenyao Zhang*, Hongsi Liu *, Bohan Li *, Jiawei He, Zekun Qi, Yunnan Wang, Shengyang Zhao , Xinqiang Yu , Wenjun Zeng Xin Jin, International Conference on Computer Vision (ICCV 2025) [arXiv] [Code] we propose Hybrid-depth, a novel framework that systematically integrates foundation models (CLIP and DINO) to extract visual priors and acquire sufficient contextual information for self-supervised depth estimation methods. This method achieve SOTA accuracy on KITTI and boost downstream perception. |

|
Jiawei He*, Danshi Li*, Xinqiang Yu*, Zekun Qi, Wenyao Zhang, Jiayi Chen, Zhaoxiang Zhang, Zhizheng Zhang, Li Yi He Wang, International Conference on Computer Vision (ICCV 2025) Highlight [arXiv] [Code] We introduce DexVLG, a vision‑language‑grasp model trained on the 170M‑pose, 174k‑object dataset that can generate instruction‑aligned dexterous grasp poses and achieves SOTA success and part‑grasp accuracy. |
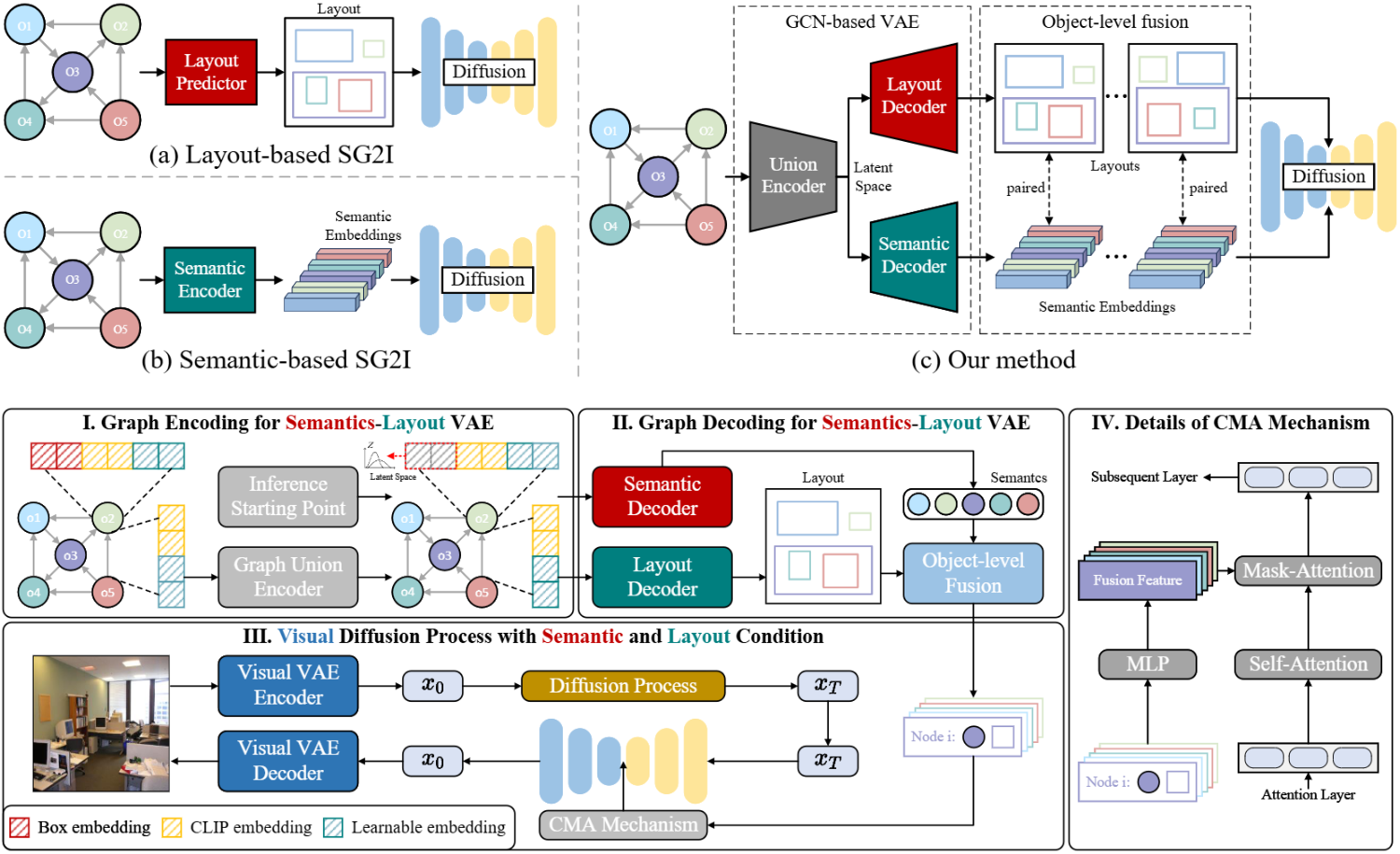 |
Yunnan Wang, Ziqiang Li, Wenyao Zhang, Zequn Zhang, Baao Xie, Xihui Liu, Wenjun Zeng, Xin Jin Annual Conference on Neural Information Processing Systems (NeurIPS 2024) Spotlight [arXiv] [Code] We propose a framework that disentangles scene graphs into semantic components and recomposes them to achieve complex, generalizable image generation. |
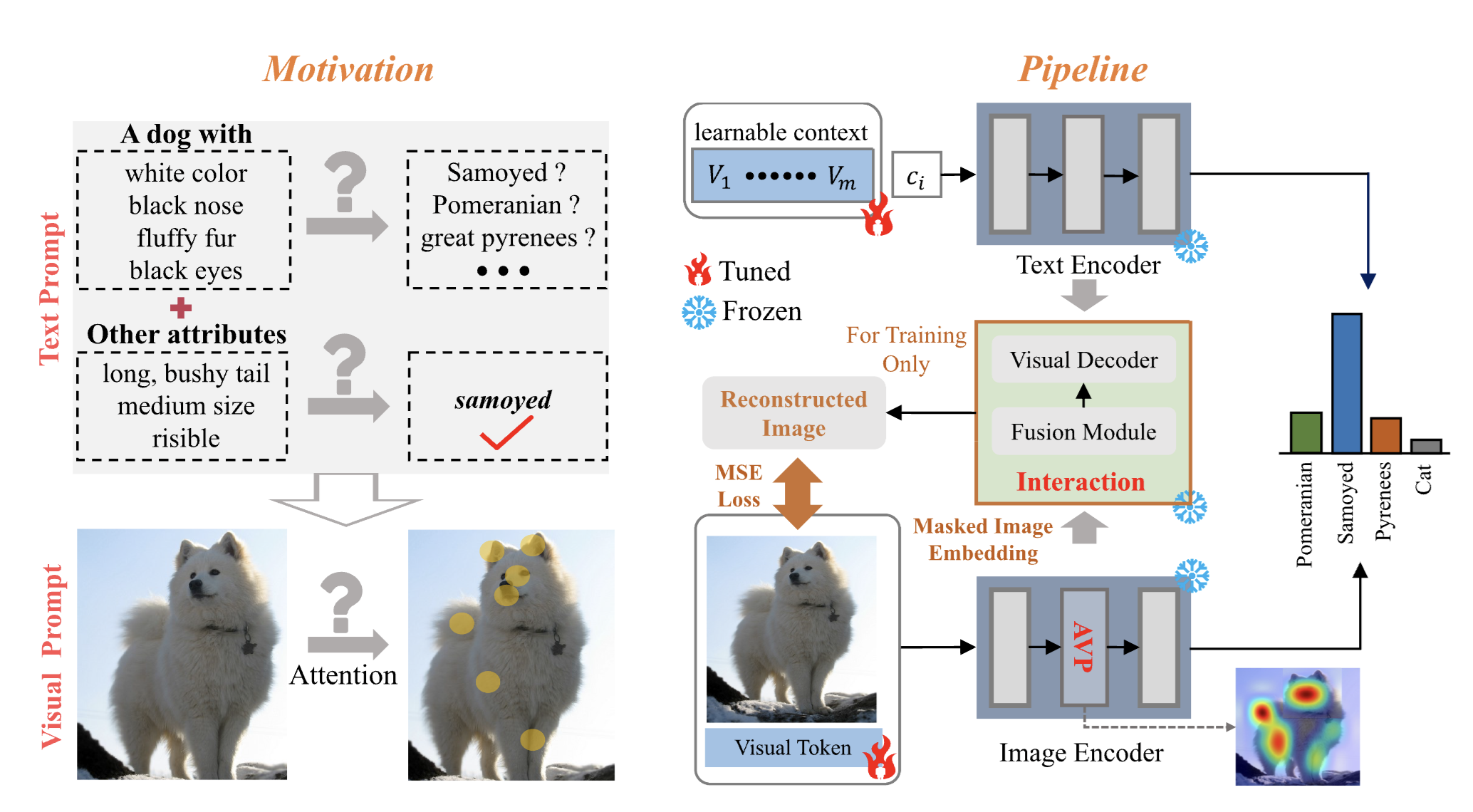 |
Wenyao Zhang, Letian Wu , Zequn Zhang, Tao Yu, Chao Ma, Xin Jin, Xiaokang Yang, Wenjun Zeng IEEE Transactions on Multimedia (TMM 2024) [Paper] [Code] We propose a framework that transfers VLMs to downstream tasks by designing visual prompts from an attention perspective that reduces the transfer solution space. |
|
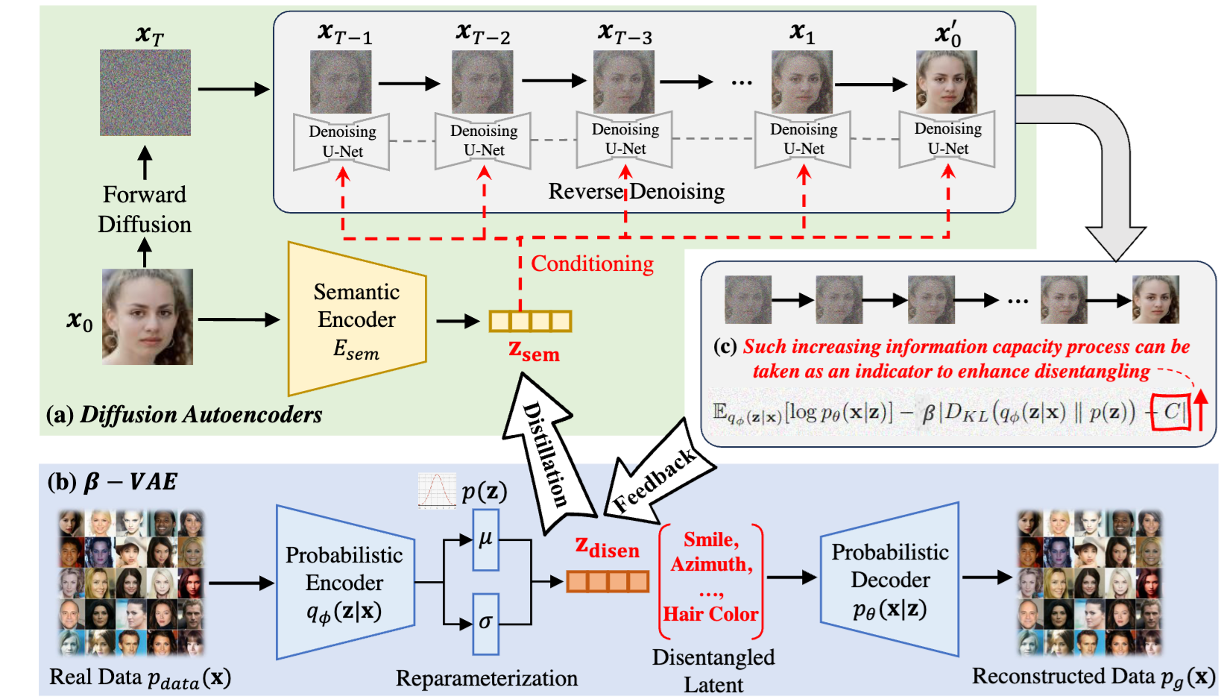
Xin Jin, Bohan Li, Baao Xie, Wenyao Zhang, Jinming Liu, Ziqiang Li, Tao Yang, Wenjun Zeng European Conference on Computer Vision (ECCV 2024) [Paper] [Code] We introduce CL-Dis, a closed-loop unsupervised disentanglement framework that integrates β-VAE distillation with diffusion-based feedback to learn semantically disentangled representations without labels. |
|
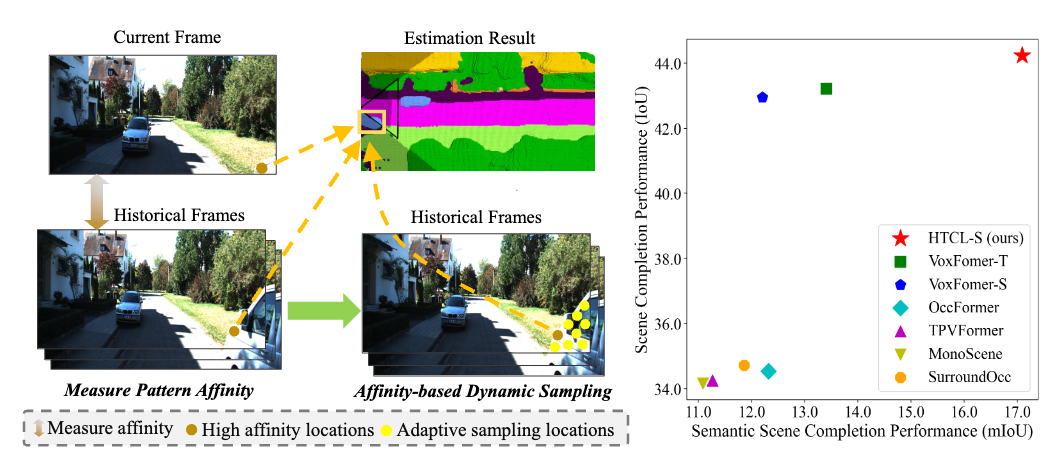
Bohan Li, Jiajun Deng, Wenyao Zhang, Zhujin Liang, Dalong Du, Xin Jin, Wenjun Zeng European Conference on Computer Vision (ECCV 2024) [Paper] [Code] We introduce HTCL, a hierarchical temporal context learning paradigm for camera-based 3D semantic scene completion. |
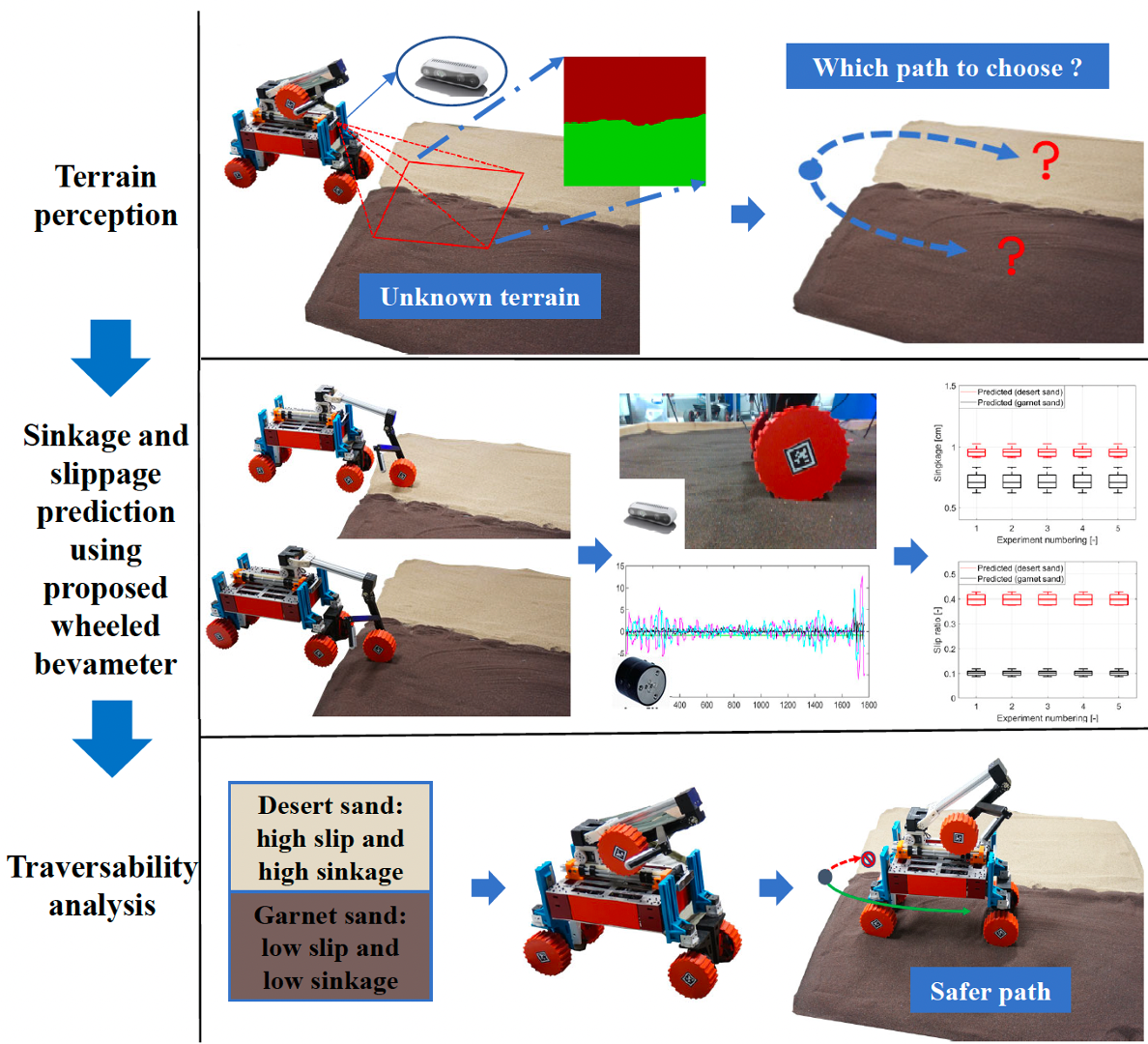 |
Wenyao Zhang, Shipeng Lyv , Feng Xue, Chen Yao, Zheng Zhu, Zhenzhong Jia IEEE Robotics and Automation Letters (RA-L 2022) & IEEE International Conference on Robotics and Automation (ICRA 2023) [Paper] [Code] We propose an on-board mobility prediction approach using an articulated wheeled bevameter that consists of a force-controlled arm and an instrumented bevameter (with force and vision sensors) as its end-effector. |
|
I received my Ph.D. from the joint program between Shanghai Jiao Tong University and Eastern Institute of Technology, Ningbo, under the supervision of Wenjun Zeng and Xiaokang Yang . I collaborate closely with Xin Jin, Chao Ma and Zekun Qi. From June. 2024 to Mar. 2026, I was an intern at Galbot, working with Li Yi, Zhizheng Zhang, He Wang. From Mar. 2026 to June. 2026, I was an intern at Tencent Robotics X, working with He Zhang and Han Hu. My research focuses on Robot Learning, Representation Learning and Multimodal Large Language Models. Email / Google Scholar / Github / X |

|
|
|
|
* indicates equal contribution & ^ indicates project lead Show Selected / Show by Date |
|
Zili Lin, Wenyao Zhang^, Yuyang Zhang, Zekun Qi, Junyan Lin, Hanxin Zhu, Jiaolong Yang, Zhibo Chen, Yao Mu, Xiaokang Yang, Xin Jin, Wenjun Zeng ArXiv Preprint, 2026 [arXiv] [Project Page] [Code] [Huggingface] We introduce DeformGen, a dynamics-based augmentation framework for deformable manipulation that generates physically plausible topology variations and warps manipulation trajectories through deformation fields to improve policy generalization from limited demonstrations. |
|
|
Yuyang Zhang*, Wenyao Zhang*^, Zekun Qi, He Zhang, Haitao Lin, Jingbo Zhang, Yao Mu, Xiaokang Yang, Wenjun Zeng, Xin Jin ArXiv Preprint, 2026 [arXiv] [Project Page] [Code] [Huggingface] We introduce ImageWAM, a simple world-action model that repurposes pretrained image editing models for robot action prediction, using editing KV caches as compact world-action context to reduce inference cost while improving policy performance. |
|
|
|
Jingwen Sun*, Wenyao Zhang*, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, Zhibo Chen European Conference on Computer Vision (ECCV 2026) [arXiv] [Project Page] [Code] We introduce VLA-JEPA, a JEPA-style pretraining framework that learns action-relevant transition semantics by predicting future latent states without pixel reconstruction or information leakage, achieving consistent gains in generalization and robustness over existing methods. |
|
Zekun Qi*, Xuchuan Chen*, Dairu Liu*, Chenghuai Lin*, Yunrui Lian, Sikai Liang, Zhikai Zhang, Yu Guan, Jilong Wang, Wenyao Zhang, Xinqiang Yu, He Wang, Li Yi IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2026) [arXiv] [Project Page] [Code] We introduce Humanoid-GPT, a GPT-style Transformer with causal attention trained on a 2B-frame retargeted motion corpus for whole-body control, achieving unprecedented zero-shot generalization to unseen motions and control tasks. |
|
|
|
Baorui Peng*, Wenyao Zhang*^, Liang Xu, Zekun Qi, Jiazhao Zhang, Hongsi Liu, Wenjun Zeng, Xin Jin ArXiv Preprint, 2026 [arXiv] We introduce ReWorld, a framework that employs reinforcement learning to align video-based embodied world models with physical realism, task completion capability, embodiment plausibility, and visual quality through a hierarchical reward model trained on a large-scale video preference dataset. |
|
|
Wenyao Zhang*, Bozhou Zhang*, Zekun Qi, Wenjun Zeng, Xin Jin, Li Zhang, International Conference on Learning Representations (ICLR 2026) [paper] [Code] [Huggingface] We propose DeFI, decoupling visual forward and inverse dynamics pretraining with a General Forward Dynamics Model (GFDM) for future prediction and a General Inverse Dynamics Model (GIDM) for latent actions from video, then unified finetuning for robot manipulation. |
|
|
Wenyao Zhang*, Hongsi Liu*, Zekun Qi*, Yunnan Wang*, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, Xin Jin Annual Conference on Neural Information Processing Systems (NeurIPS 2025) [arXiv] [Project Page] [Code] We recast the vision–language–action model as a perception–prediction–action model and make the model explicitly predict a compact set of dynamic, spatial and high- level semantic information, supplying concise yet comprehensive look-ahead cues for planning. |
|
Zekun Qi*, Wenyao Zhang*, Yufei Ding*, Runpei Dong, Xinqiang Yu, Jingwen Li, Lingyun xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang, He Wang, Li Yi Annual Conference on Neural Information Processing Systems (NeurIPS 2025) Spotlight [arXiv] [Project Page] [Code] [Huggingface] We introduce the concept of semantic orientation, representing the object orientation condition on open vocabulary language. |
|
|
|
Wenyao Zhang*, Hongsi Liu *, Bohan Li *, Jiawei He, Zekun Qi, Yunnan Wang, Shengyang Zhao , Xinqiang Yu , Wenjun Zeng Xin Jin, International Conference on Computer Vision (ICCV 2025) [arXiv] [Code] [Huggingface] we propose Hybrid-depth, a novel framework that systematically integrates foundation models (CLIP and DINO) to extract visual priors and acquire sufficient contextual information for self-supervised depth estimation methods. This method achieve SOTA accuracy on KITTI and boost downstream perception. |
 |
Wenyao Zhang, Letian Wu , Zequn Zhang, Tao Yu, Chao Ma, Xin Jin, Xiaokang Yang, Wenjun Zeng IEEE Transactions on Multimedia (TMM 2024) [Paper] [Code] We propose a framework that transfers VLMs to downstream tasks by designing visual prompts from an attention perspective that reduces the transfer solution space. |
| |
Wenyao Zhang, Shipeng Lyv , Feng Xue, Chen Yao, Zheng Zhu, Zhenzhong Jia IEEE Robotics and Automation Letters (RA-L 2022) & IEEE International Conference on Robotics and Automation (ICRA 2023) [Paper] [Code] We propose an on-board mobility prediction approach using an articulated wheeled bevameter that consists of a force-controlled arm and an instrumented bevameter (with force and vision sensors) as its end-effector. |
|
|