ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
1Shanghai Jiao Tong University
2Eastern Institute of Technology
3Tencent Robotics X
4Tsinghua University
5Zhongguancun Academy
* Equal contribution · † Project lead · ✉ Corresponding author
Abstract
World-action reasoning without dense future-video tokens
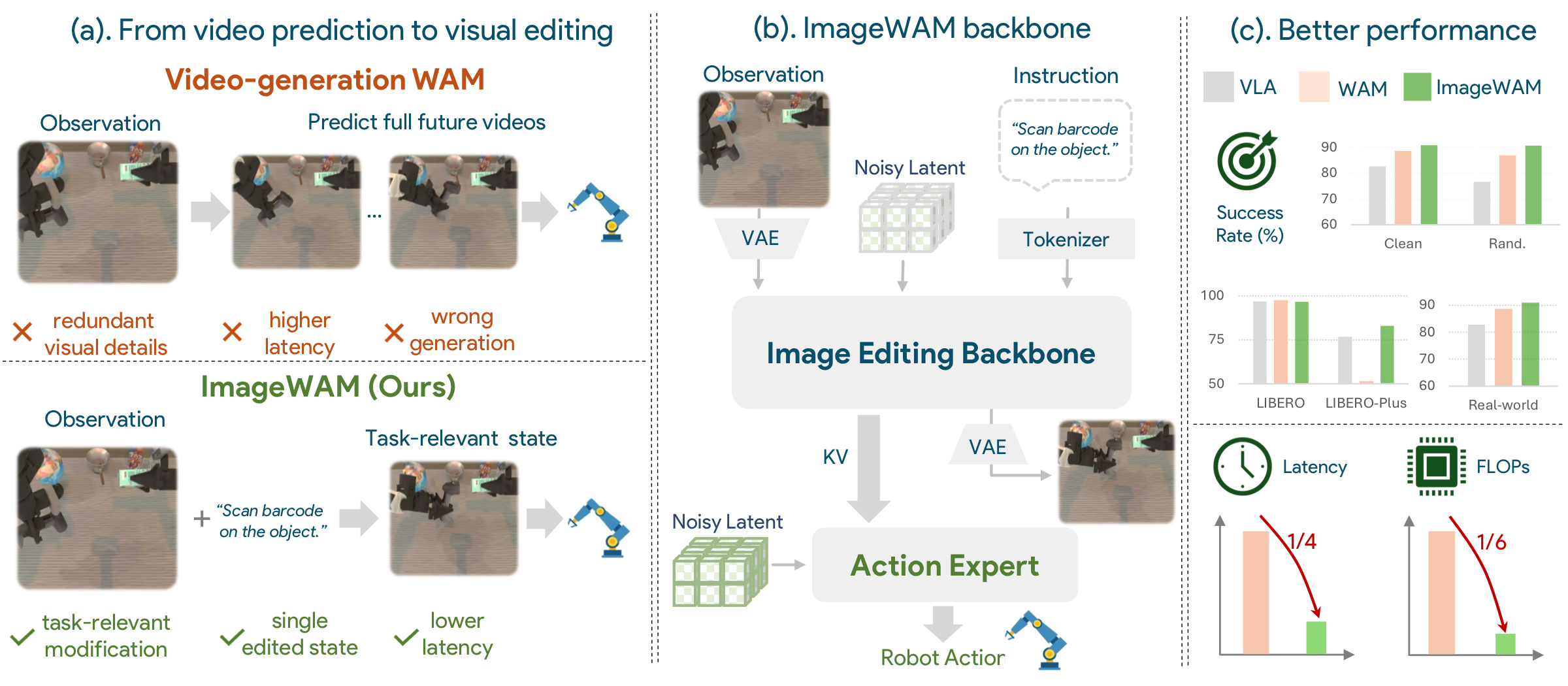
World Action Models (WAMs) often rely on video generation to bridge visual world modeling and robot control. This design is intuitive but expensive: dense multi-frame future tokens increase latency, full video prediction spends capacity on action-irrelevant appearance details, and long-horizon imagination can introduce visual errors that mislead action prediction.
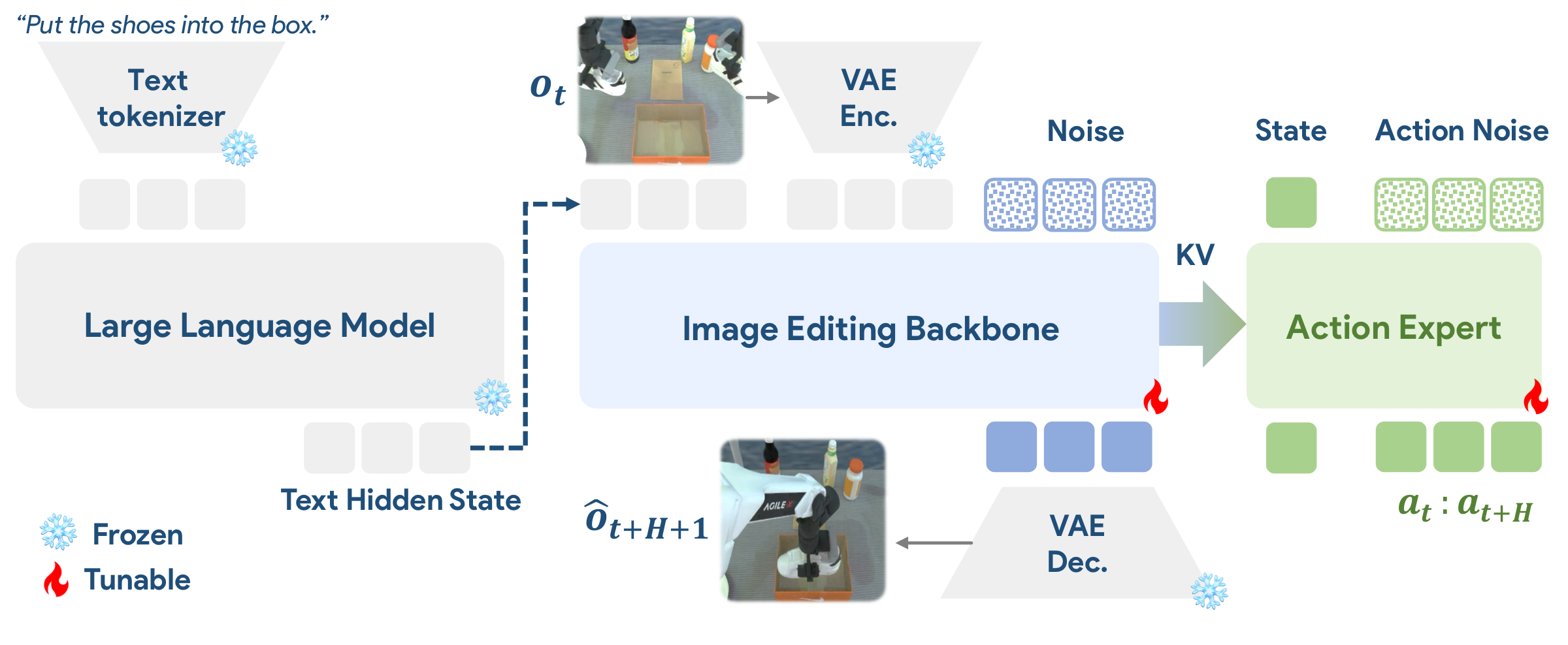
ImageWAM asks whether WAMs really need video generation. It uses pretrained image editing models as robot policy backbones, because editing is naturally source-grounded, instruction-guided, and change-centric. During inference, ImageWAM does not decode the edited target frame. It takes the KV caches produced by a single image-editing forward step as compact world-action context, then uses a flow-matching action expert to generate future robot actions.
Method
Image editing as an action-relevant visual transformation prior
A manipulation instruction usually specifies what should change in the scene. ImageWAM transfers this instruction-to-change prior from image editing into robot control.
Current-state grounding
The editing backbone is conditioned on the current observation, preserving source-image context while focusing on task-relevant edits.
Instruction-guided change
Language specifies the target transformation, encouraging features that encode object motion, spatial rearrangement, and contact-relevant changes.
Compact inference
At test time, ImageWAM uses one editing forward step and internal KV caches, avoiding dense future-video denoising and decoding.
Model family
The codebase supports FLUX.2 ImageWAM, OmniGen2 ImageWAM, and Ovis-U1 ImageWAM. FLUX.2 provides 4B and 9B variants; Ovis-U1 is the smallest variant with a 1.1B image-editing DiT while remaining competitive in many settings.
Implementation signal from code
The implementation wraps editing backbones as video/editing experts, pairs them with ActionDiT-style action experts, and mixes them through a Mixture-of-Transformers interface. FLUX.2 uses a slim compatible action expert with matched attention dimensions and a flow-matching action scheduler.
Results
Strong policy performance with a cheaper world-action intermediate
ImageWAM is evaluated on LIBERO, LIBERO-Plus, RoboTwin 2.0, and real-world dual-arm manipulation without extra embodied policy pretraining.
RoboTwin 2.0
| Method | P.T. | Clean | Rand. | Avg. |
|---|---|---|---|---|
| π0 | ✓ | 65.92 | 58.40 | 62.16 |
| π0.5 | ✓ | 82.74 | 76.76 | 79.75 |
| FastWAM | × | 91.88 | 91.78 | 91.83 |
| ImageWAM | × | 92.65 | 93.70 | 93.18 |
LIBERO
| Method | Spatial | Object | Goal | Long | Avg. |
|---|---|---|---|---|---|
| π0.5 | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| LingBot-VA | 98.5 | 99.6 | 97.2 | 98.5 | 98.5 |
| Fast-WAM | 98.2 | 100.0 | 97.0 | 95.2 | 97.6 |
| ImageWAM | 97.2 | 99.2 | 98.8 | 98.4 | 98.4 |
LIBERO-Plus robustness
| Variant | Camera | Language | Noise | Layout | Avg. |
|---|---|---|---|---|---|
| ImageWAM OmniGen2 | 80.0 | 70.9 | 77.1 | 71.8 | 71.8 |
| ImageWAM Ovis-U1 | 63.3 | 75.4 | 75.2 | 74.6 | 71.2 |
| ImageWAM FLUX.2 4B | 80.8 | 91.4 | 93.8 | 80.5 | 83.1 |
| ImageWAM FLUX.2 9B | 79.8 | 95.2 | 93.3 | 83.1 | 85.2 |
Real robot & efficiency
| Item | FastWAM | ImageWAM |
|---|---|---|
| Real-world avg. | 79.0% | 84.5% |
| Latency | Baseline | 4.1× faster / 1.15× faster* |
| FLOPs | Baseline | 84.7% less / 26.4% less* |
| Intermediate | Video or cache | Editing cache |
* FastWAM-IDM uses video intermediates; FastWAM 1-step uses cache intermediates.


Analysis
Why editing caches help
Task-relevant attention
Paper analysis shows ImageWAM concentrates attention on manipulated objects, target receptacles, and contact regions, while suppressing action-irrelevant background.
Avoiding future-video artifacts
Because inference does not decode dense future frames, the action expert is less exposed to geometry/layout artifacts that can appear in imagined video rollouts.

Release
Code and checkpoints
ImageWAM code and model releases are available through GitHub and Hugging Face.
Citation
BibTeX
@article{zhang2026imagewam,
title = {ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?},
author = {Zhang, Yuyang and Zhang, Wenyao and Qi, Zekun and Zhang, He and Lin, Haitao and Zhang, Jingbo and Mu, Yao and Yang, Xiaokang and Zeng, Wenjun and Jin, Xin},
year = {2026}
}