|
I am actively seeking full-time research scientist positions in computer vision, MLLM and robotics learning! 预期26年6月毕业, 如果您有高校或企业关于计算机视觉, 多模态大语言模型以及机器人学习的教职/研发/博后岗位,请联系我! I'm a final year PhD student of the joint program between Shanghai Jiao Tong University and Eastern Institute of Technology, Ningbo, under the supervision of Wenjun Zeng and Xiaokang Yang . I collaborate closely with Xin Jin, Li Yi, Zhizheng Zhang and He Wang. I am currently a research intern at GalBot.
Previously, I obtained my master's degrees from
Sourthern University of Science and Technoledge , supervised by Zhenzhong Jia.
And I received my bachelor's degree from Beijing Jiao Tong University , supervised by Xin Zhang.
My research focuses on Robot Learning, Representation Learning and Multimodal Large Language Models. I am looking for collaborators to work on the following topics:
If you are interested in these topics, please feel free to contact me. Email / Google Scholar / Github / |

|
|
|
|
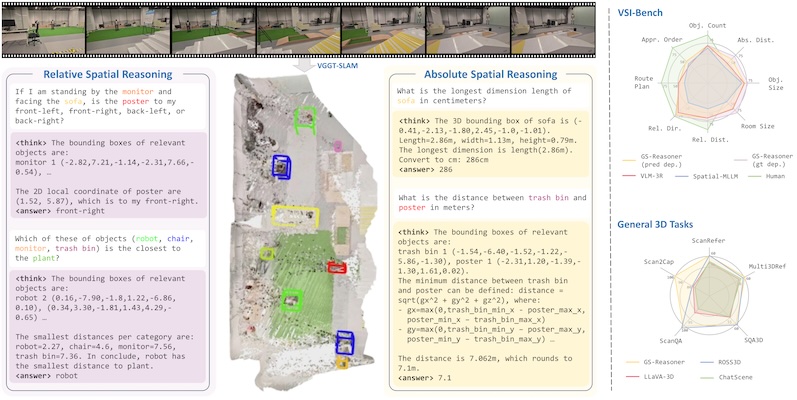
Yiming Chen, Zekun Qi, Wenyao Zhang, Xin Jin, Li Zhang, Peidong Liu ArXiv Preprint, 2025 [arXiv] [Project Page] [Code] [HuggingFace] We believe that grounding can be seen as a chain-of-thought for spatial reasoning. Based on this, we achieve a new SOTA performance on VSI-Bench. |
|
Tianyu Xu*, Jiawei Chen*, Jiazhao Zhang*, Wenyao Zhang, Zekun Qi, Minghan Li, Zhizheng Zhang, He Wang ArXiv Preprint, 2025 [arXiv] [Project Page] We present MM-Nav a multi-view VLA system with 360° perception. The model is trained on large-scale expert navigation data collected from multiple reinforcement learning agents, demonstrating robust generalization in complex navigation scenarios. |
|

|
Wenyao Zhang*, Hongsi Liu*, Zekun Qi*, Yunnan Wang*, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, Xin Jin Annual Conference on Neural Information Processing Systems (NeurIPS 2025) [arXiv] [Code] We recast the vision–language–action model as a perception–prediction–action model and make the model explicitly predict a compact set of dynamic, spatial and high- level semantic information, supplying concise yet comprehensive look-ahead cues for planning. |
|
Zekun Qi*, Wenyao Zhang*, Yufei Ding*, Runpei Dong, Xinqiang Yu, Jingwen Li, Lingyun xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang, He Wang, Li Yi Annual Conference on Neural Information Processing Systems (NeurIPS 2025) Spotlight [arXiv] [Project Page] [Code] [Huggingface] We introduce the concept of semantic orientation, representing the object orientation condition on open vocabulary language. |
|
|
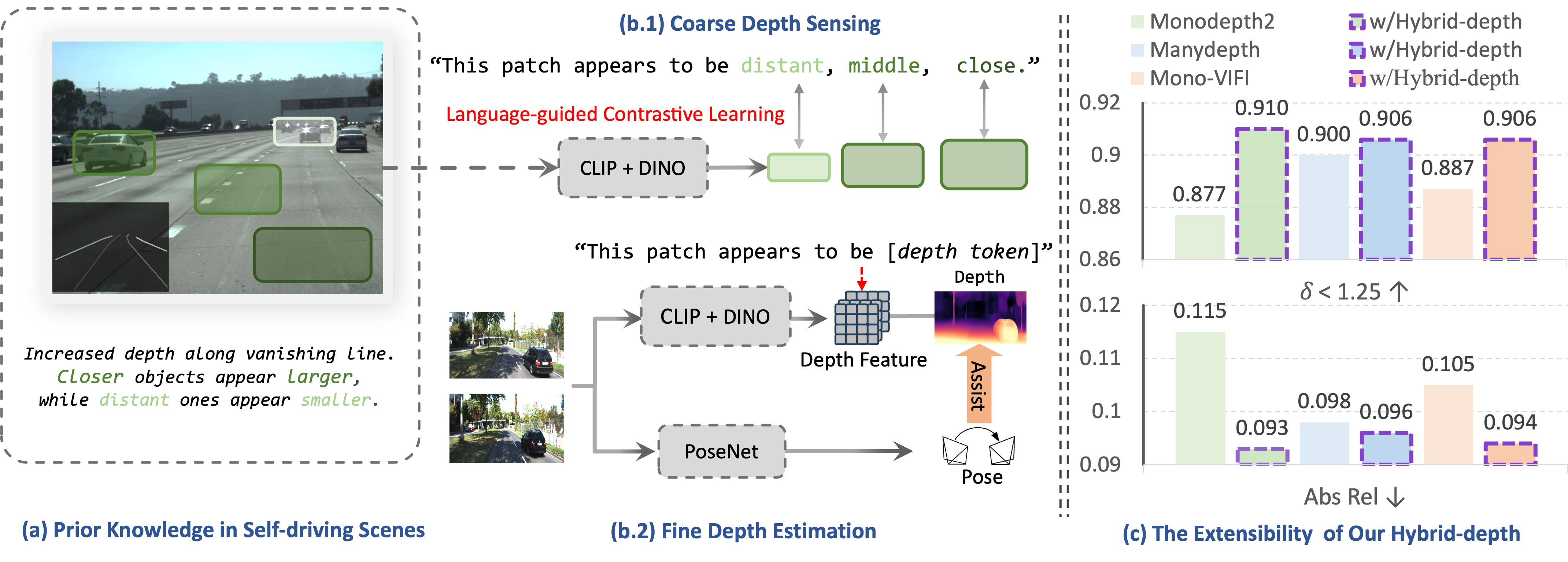
Wenyao Zhang*, Hongsi Liu *, Bohan Li *, Jiawei He, Zekun Qi, Yunnan Wang, Shengyang Zhao , Xinqiang Yu , Wenjun Zeng Xin Jin, International Conference on Computer Vision (ICCV 2025) [arXiv] [Code] we propose Hybrid-depth, a novel framework that systematically integrates foundation models (CLIP and DINO) to extract visual priors and acquire sufficient contextual information for self-supervised depth estimation methods. This method achieve SOTA accuracy on KITTI and boost downstream perception. |

|
Jiawei He*, Danshi Li*, Xinqiang Yu*, Zekun Qi, Wenyao Zhang, Jiayi Chen, Zhaoxiang Zhang, Zhizheng Zhang, Li Yi He Wang, International Conference on Computer Vision (ICCV 2025) Highlight [arXiv] [Code] We introduce DexVLG, a vision‑language‑grasp model trained on the 170M‑pose, 174k‑object dataset that can generate instruction‑aligned dexterous grasp poses and achieves SOTA success and part‑grasp accuracy. |
|
Mengdi Jia*, Zekun Qi*, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, Li Yi arXiv preprint, 2025 [arXiv] [Project Page] [Code] [Huggingface] Based on cognitive psychology, we introduce a comprehensive and complex spatial reasoning benchmark, including 50 detailed categories and 1.5K manual labeled QA pairs. |
|
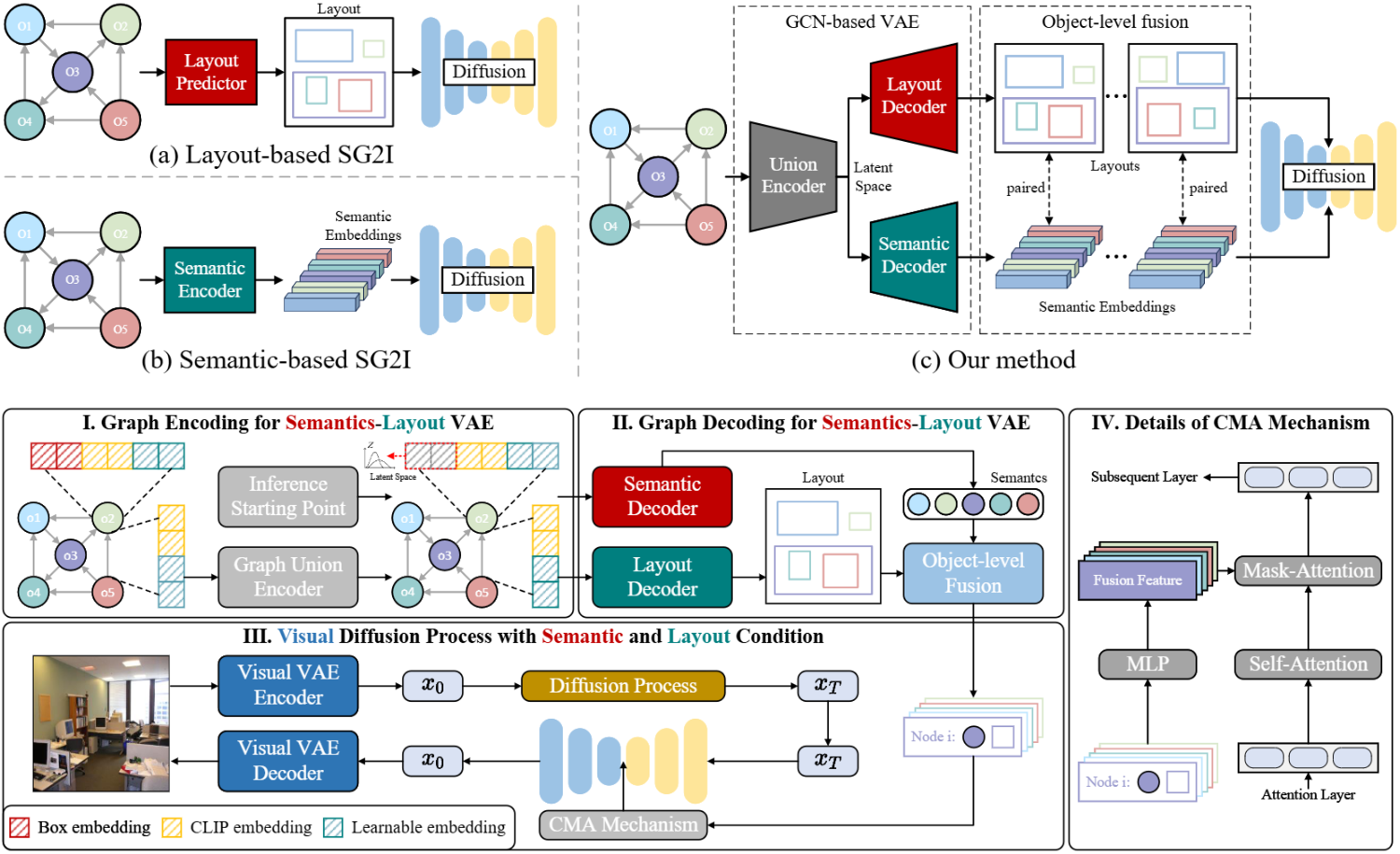 |
Yunnan Wang, Ziqiang Li, Wenyao Zhang, Zequn Zhang, Baao Xie, Xihui Liu, Wenjun Zeng, Xin Jin Annual Conference on Neural Information Processing Systems (NeurIPS 2024) Spotlight [arXiv] [Code] We propose a framework that disentangles scene graphs into semantic components and recomposes them to achieve complex, generalizable image generation. |
 |
Wenyao Zhang, Letian Wu , Zequn Zhang, Tao Yu, Chao Ma, Xin Jin, Xiaokang Yang, Wenjun Zeng IEEE Transactions on Multimedia (TMM 2024) [Paper] [Code] We propose a framework that transfers VLMs to downstream tasks by designing visual prompts from an attention perspective that reduces the transfer solution space. |
|
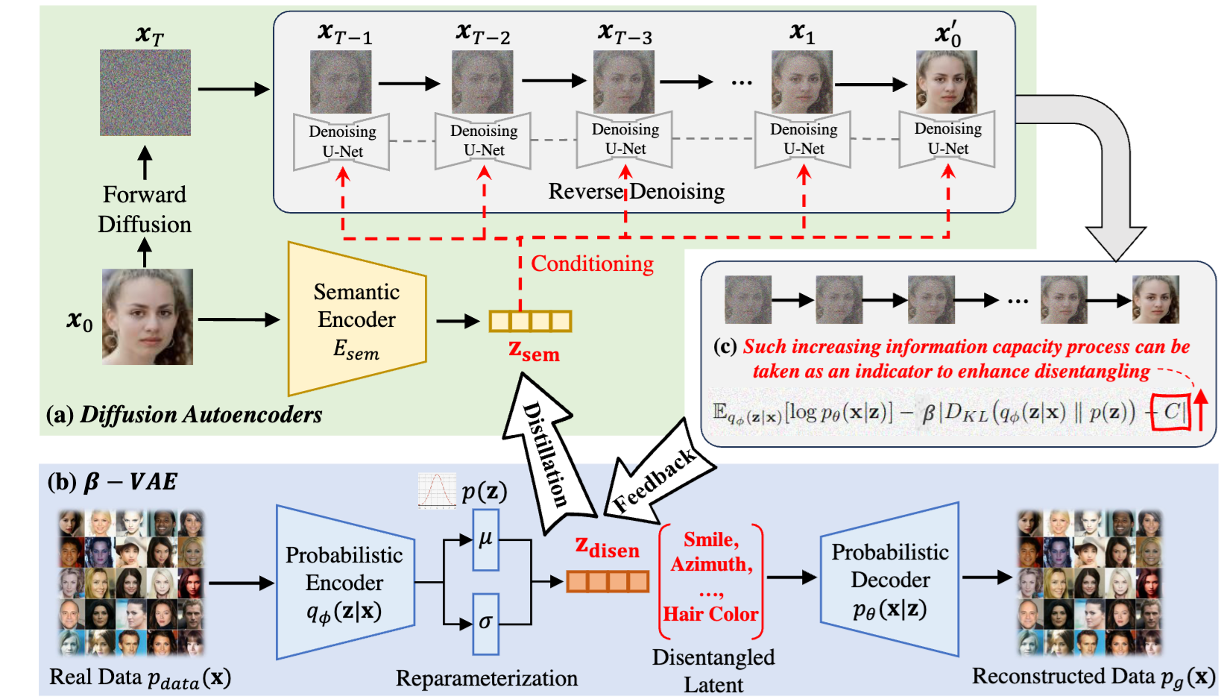
Xin Jin, Bohan Li, Baao Xie, Wenyao Zhang, Jinming Liu, Ziqiang Li, Tao Yang, Wenjun Zeng European Conference on Computer Vision (ECCV 2024) [Paper] [Code] We introduce CL-Dis, a closed-loop unsupervised disentanglement framework that integrates β-VAE distillation with diffusion-based feedback to learn semantically disentangled representations without labels. |
|
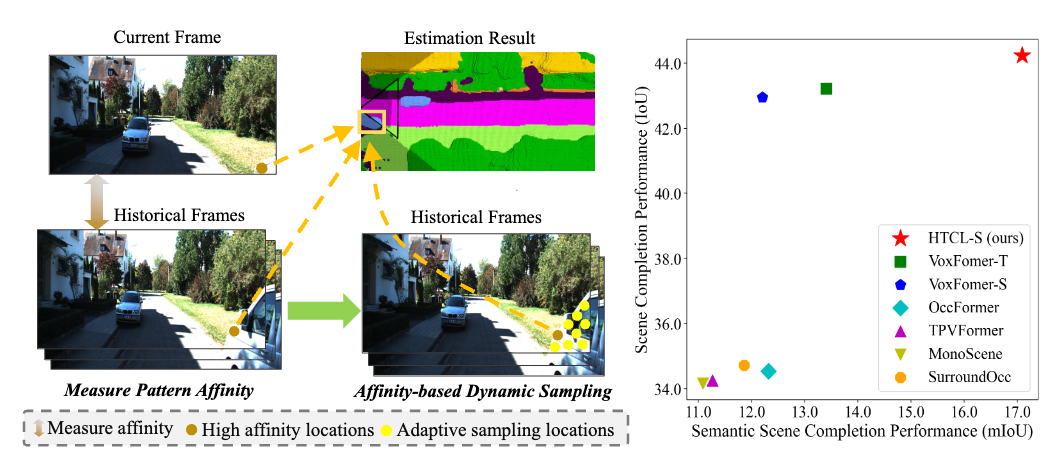
Bohan Li, Jiajun Deng, Wenyao Zhang, Zhujin Liang, Dalong Du, Xin Jin, Wenjun Zeng European Conference on Computer Vision (ECCV 2024) [Paper] [Code] We introduce HTCL, a hierarchical temporal context learning paradigm for camera-based 3D semantic scene completion. |
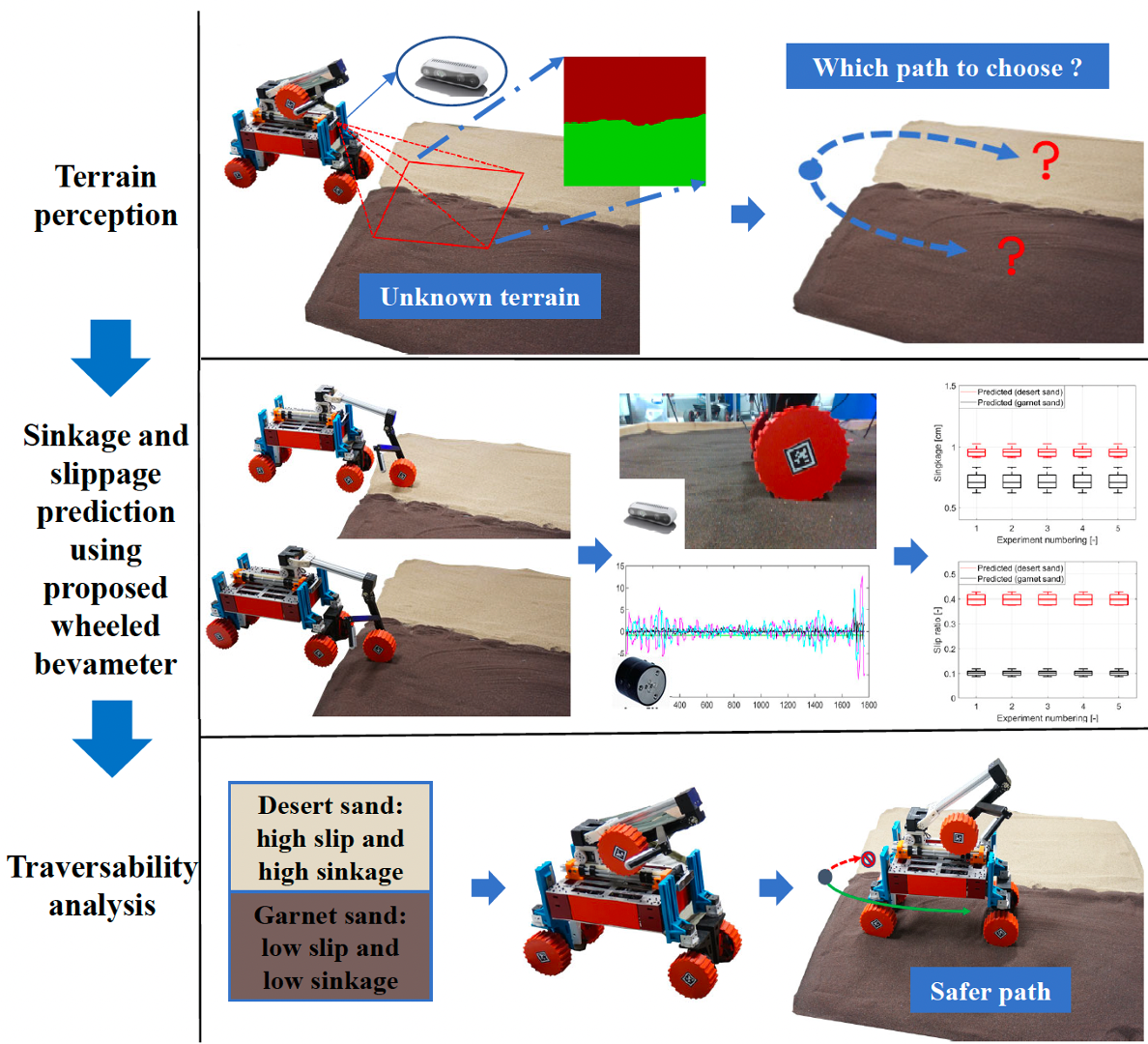 |
Wenyao Zhang, Shipeng Lyv , Feng Xue, Chen Yao, Zheng Zhu, Zhenzhong Jia IEEE Robotics and Automation Letters (RA-L 2022) & IEEE International Conference on Robotics and Automation (ICRA 2023) [Paper] [Code] We propose an on-board mobility prediction approach using an articulated wheeled bevameter that consists of a force-controlled arm and an instrumented bevameter (with force and vision sensors) as its end-effector. |
|
|